
Share this article



You’ve almost certainly used the Flexibits parser at some point: the natural language engine that allows Fantastical and Cardhop to take a certain action based on your text input.
It looks like magic… but how does Fantastical know what to do when you’re typing out the information for your next dentist appointment?
Enter natural language processing!
Broadly speaking, natural language processing (often abbreviated as NLP) is a set of tools and techniques for helping computers use and understand “natural” language; that is, language the way humans naturally use it.
NLP methods can be split into two fields: helping computers interpret natural language inputs, and allowing computers to generate natural language as an output.

NLP methodologies can also be categorized into dealing with text or speech, either as inputs or outputs. Here are some examples you’re probably familiar with:
There’s an amazing amount of different techniques being developed to tackle each of these specific NLP applications in fields ranging from data science to computational linguistics to spectrographic analysis.
In particular, the problem of helping computers understand and use speech requires pretty sophisticated science, since the way humans talk varies widely from person to person and is hard for computers to replicate.

Computers are generally better equipped to deal with text, rather than speech — text is easier to turn into structured data because there are less factors like pronunciation, inflection, and emotions affecting how language is represented in text.
At Flexibits, we get to focus on doing the best possible job of getting a computer to understand your text-based input. We don’t need Fantastical or Cardhop to talk back to you (yet…?), we just want them to take the correct action based on what you type into the parser.
Even though we do have some shortcuts like task and /calendarname, our goal is to make sure you can use as natural language as possible when typing in your commands. There’s a reason it’s called “natural” language processing!
💡 Did you know?
On Fantastical, you can use the /calendarname shortcut to add an event to a specific calendar, and the task shortcut to quickly add a task.
🧠 Tips & Tricks
Check out this support article for even more tips and tricks about how to get the most out of our natural language engine.
We can teach a computer to understand natural language by building a language model that dictates how a computer should attempt to understand language inputs.
Rules-based models are, as you’d imagine, taught all of the rules of a language. Definitions of words, grammatical rules, conventions, and more can all be directly programmed into a language model.
Machine learning models are built by giving a model a ton of data, and then it learns (either with help from the programmers or completely on its own) how to understand language based on that data.
Given the enormous quantities of data that we generate on the internet every day, many language models in use today are what’s known as large language models (LLMs), where the “large” refers to the quantity of data used to train them. Most of the predictive language models you encounter on a daily basis are LLMs — like when a search bar tries to guess the rest of your query, or your phone tries to finish your text for you.
As for the natural language engine powering the Flexibits parser, we think it’s the best of both worlds: it’s a machine learning model with additional rules on top of it.
Our natural language engine does not do any predicting or contextual guessing like an LLM would. That’s because building an LLM with predictive capabilities often requires collecting a ton of data from your users, and as you probably know, we like to collect as little of your data as possible.
LLMs also rely on huge servers for their natural language processing tasks. By contrast, the Flexibits parser is able to run directly on your device, meaning any data you enter into Fantastical or Cardhop stays completely private — and it usually means our parser is able to work a little faster than an LLM, too.
Here’s a very basic breakdown of natural language processing as it applies to our use case here at Flexibits.
Step 1: Processing the input
The text input is broken down into small chunks of data that a computer can understand.

This is where the computer starts to separate out which words contain key information (Drinks, Lila, Thurs), and which are referential clues (with, on, at).
Step 2: Analyzing the Input
Using its understanding of natural language, the model will now attempt to interpret the information contained in the input.

As you can see, a model’s understanding of grammar comes in handy here. The word “with” is a good indicator that the next input is a person; the word “at” typically will be followed by a time or a place.
Note that you wouldn’t need to type out all of “Thursday” or “PM” for the parser to know what you mean thanks to the flexibility of the natural language engine!
Step 3: Performing the Action
Now that the model understands the input, the program can do what it believes you are telling it to do.
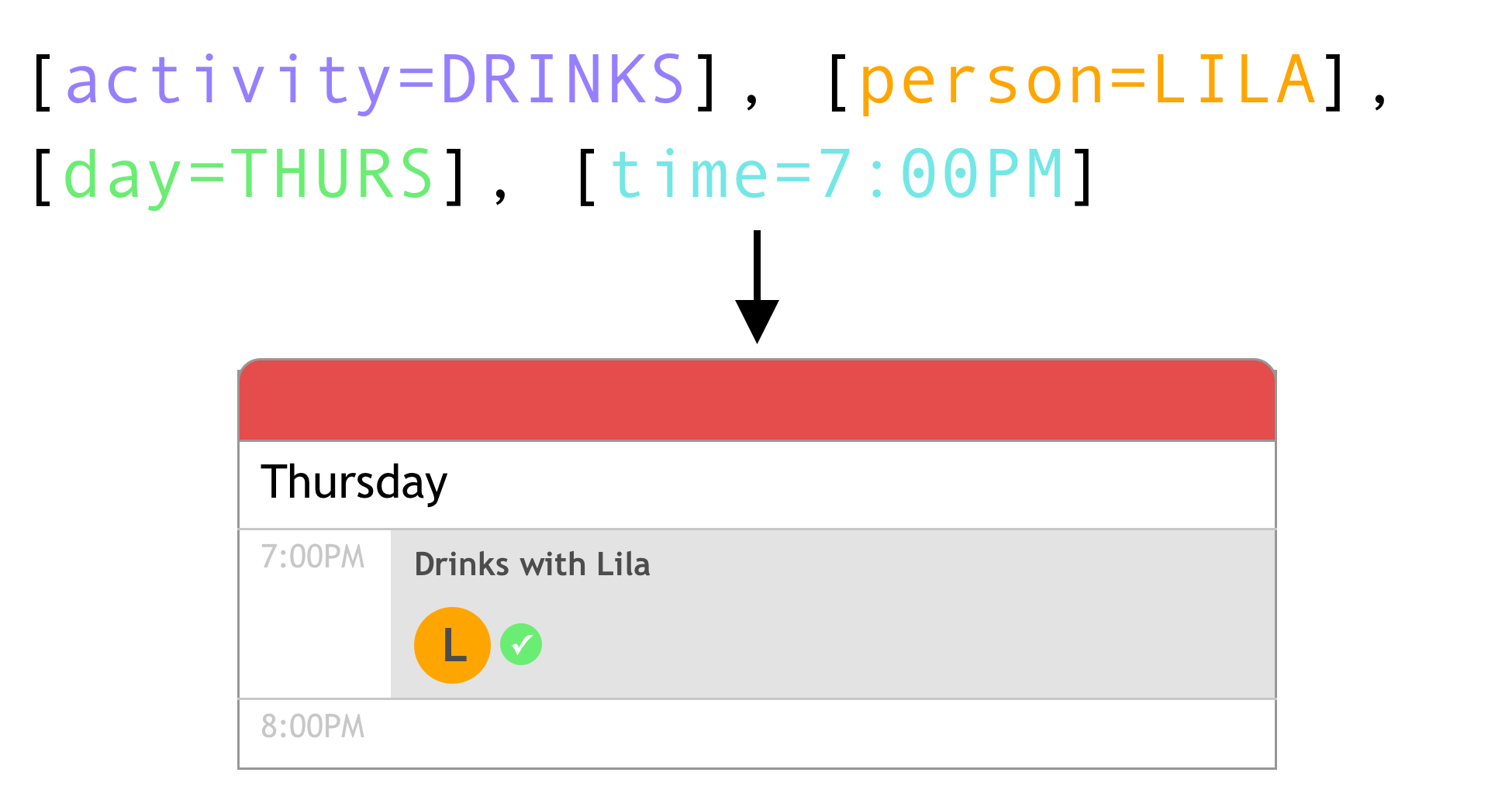
When you use the parser in Fantastical and Cardhop, you can watch the action being teed up while you enter words in the parser, which is a helpful way to make sure you and the computer are on the same page. 🤖✅
More complicated examples
“Drinks with Lila on Thurs at 7P” is a pretty simple example, but the parser is able to understand more complex commands as well.
Adding a repeating event:
“Book Club every Thursday at 6:30PM from October 5 to December 21″
The parser can understand words like “every,” “from,” and “to” to add repeating events to your calendar.
Adding an event that starts and ends in different time zones:
“Flight from 9:35A PT to 5:41P ET“
Time zones are a good examples of something that can be frustrating to communicate between humans, but that computers have no problem with.
Yes and no. The term “artificial intelligence” is hard to pin down in the first place, and natural language processing consists of a lot of different methods and applications, as we’ve seen.
Researchers often distinguish between two types of artificial intelligence.
These are not hard and fast boundaries, of course. SmarterChild was a decent example of an ANI for text-based language in 2000, but ChatGPT, while technically also an ANI, has come leaps and bounds closer to being “generally” intelligent in that field.
On to the question on everyone’s mind — is the Flexibits parser a form of artificial intelligence?
Believe it or not, there’s debate on that question even within our own offices. Ultimately, the answer depends on how you define artificial intelligence. It’s pertinent to note that the definition of “artificial intelligence” has evolved alongside the technologies the term is meant to describe.
If you define artificial intelligence as a machine that is able to problem-solve completely on its own, then you’d fall in the “no, our parser is not artificial intelligence” camp. It simply does what you tell it to do when you type in your commands in the parser.
Or, you could take a broader definition of artificial intelligence: a machine that performs tasks that a human would typically perform. By this definition, you might say that we’ve been pioneering artificial intelligence since way back in 2010 — before it was cool. 😎
However you define it, rest assured that the parser is smart enough and flexible enough to understand your natural language input, even when you type complex commands. So keep typing in your natural human way, let us know if you ever have trouble with the parser, and don’t worry about our natural language engine taking over the world anytime soon!

